简介
$sample是MongoDB内置的一个操作,可供用户使用,能够很方便地在内核侧对一个collection中(对应关系型数据库中的table)的数据进行采样。比如之前做索引推荐的时候,需要通过采样来了解一个collection中数据的分布情况,进而计算最优索引。便分析了$sample在MongoDB内核中的实现,在此总结成文。这篇文章先从MongoDB底层存储细节讲起,然后深入剖析$sample的实现,最后给出$sample的正确使用方法和注意事项。
这篇文章适用于想了解MongoDB内核的初学者,以及想使用MongoDB内核$sample操作的开发者,希望能给大家带来启发。文章如有遗漏谬误之处敬请指教。
1. MongoDB的存储引擎
为了更好地理解$sample操作的实现细节,下面先介绍一下MongoDB的存储引擎,让大家对MongoDB是如何存储数据有一个直观的认识。
MongoDB是一款开源的面向文档的DBMS,也是目前排名最高的NoSQL DBMS。它可以存储和管理海量的类似于JSON的文档。数据的底层存储格式为BSON,BSON是一种对JSON-like的文档进行二进制编码序列化的方法。
对数据的实际存取是由存储引擎模块负责。MongoDB的底层存储引擎是插件式的,可以更换。4.0版本之后,MMAPv1存储引擎已被弃用,目前开源版的只有WiredTiger可用。
MongoDB在2014年收购了WiredTiger团队,并从3.2版本开始,成为了MongoDB默认的存储引擎。WiredTiger的目标是一款通用的NoSQL存储引擎,其不仅支持row-oriented storage,而且支持column-oriented storage,还支持log-structured merge trees。MongoDB使用的是WiredTiger的row-oriented storage。
作为一个KV存储引擎,WiredTiger也是有column概念的,这主要是因为WiredTiger使用类似python中struct模块的方式指定key_format和value_format。format中可以使用的类型,以及在几个编程语言中的映射如下所示,
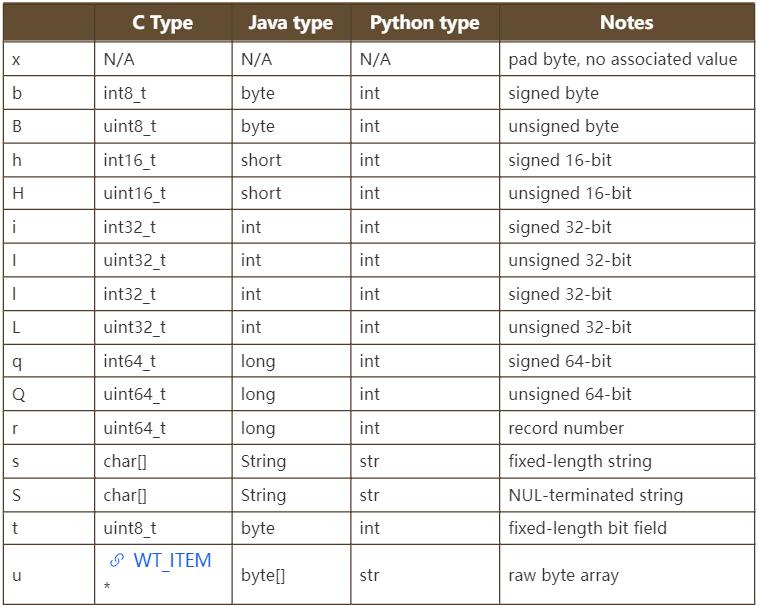
MongoDB在创建collection时,默认使用的key_format是q,也就是一个64位有符号整数,value_format固定是u。实际上,key是一个64位整数,在内核中被称为RecordId,RecordId随着数据插入从1开始单调递增。RecordId可以理解为本条数据在此collection中的位置或者唯一标识,对用户不可见。value是一个byte数组,内容就是对document按照BSON格式做二进制序列化编码后的数据。也就是说,所有对数据格式的解析、schema validation等等都是在存储引擎外层做的。
如果开启了grouped collection特性,key_format是qq,就是两个64位有符号整数。group collection特性,相比于正常情况下一个collection一个wt文件来说,这个是将若干个collection组织在一起。此时的key_format是qq,第一个64位整数代表了这条数据属于哪个collection,后面那个64位整数就是RecordId。
副本集的不同成员可以使用不同的底层存储引擎,或者使用wiredtiger不同类型的存储模型。
MongoDB也将索引数据以key/value的方式存放在WiredTiger中,默认key_format为u,value_format也是u。一个索引项就是一个key/value pair,key的组成为index data+record id,index data由被索引数据的type和 value组成。value是帮助将key转换为bson类型数据的辅助数据。插入数据时,也会插入对应的索引项。如果开启了group collection特性,key_format就是qu。
可以看出,在MongoDB中数据和索引是分开维护的,所有的索引都是非聚簇索引。但是从Monodb5.3版本开始,可以创建一个拥有聚簇索引的collection。
index是在mongo server层实现的。MongoDB server将一个个索引项视作一个个的KV,将所有的索引项存储在一个普通的“table”中,只不过这个table的key_format是u。一个索引项的KV都是从一个KeyString中取得,key是KeyString里面的_buffer(这个buffer包含了所有的与这个索引有关的values,以及在末尾处包含了record id), value是 KeyString里面的_typeBits(typebit用来将keyString恢复为Bson)。
2. 数据的访问
对于一个查询请求,MongoDB通过一系列的查询解析、查询优化,将请求分解为一个个的stage来执行。每个stage完成不同的任务,比如fetch stage就是拿着record id去collection中取出对应的document;ixscan stage就是查找index entry,并取出索引数据。
在WiredTiger层面,都是通过cursor来访问数据。不管是collection data,还是index data,MongoDB都是将其存储在WiredTiger的table里面,所以绝大多数时候MongoDB使用的都是WiredTiger的table cursor,而table cursor背后其实是一个b+tree cursor。因为WiredTiger在内存中是维护了一个B+tree的结构来组织数据。collection scan是用后序遍历的方式,扫描B+树的所有叶子节点。
MongoDB层面的cursor大体可以抽象为两种:
- seekable cursor
- random cursor
seekable cursor主要用于搜索定位数据,比如在fetch stage中拿着record id在collection中取出 document,比如在ixscan stage中拿着filter搜索指定的索引项。在WiredTiger中,搜索的过程是在B+树上进行的,一般情况下,是通过逐字节比较来进行精确定位。
从wiredtiger层面的数据组织以及比较方式来看,wiredtiger是能够返回不同类型的数据的,但是这个类型跟mongo server层面的类型不是完全一致的,而且mongo server对于返回的数据有自己的一套规则:
- 如果不指定filter,mongo server对于collection scan和index scan不对wiredtiger返回的数据做进一步过滤
- 如果指定了filter,比如lt、gt操作符,mongo server会要求数据类型和数据取值跟filter一致
random cursor是一种从当前collection中随机返回record的cursor。random cursor的核心是它的next方法,是在WiredTiger里面实现的。主要逻辑就是从B+树的根节点开始,每次都随机选择一个子节点,直到当前节点是一个叶子结点,这个过程可以称为“random descent”。最后从此叶子结点中随机选择一个key/value pair并返回。代码可以见__wt_btcur_next_random、__wt_random_descent函数。示意图如下所示。
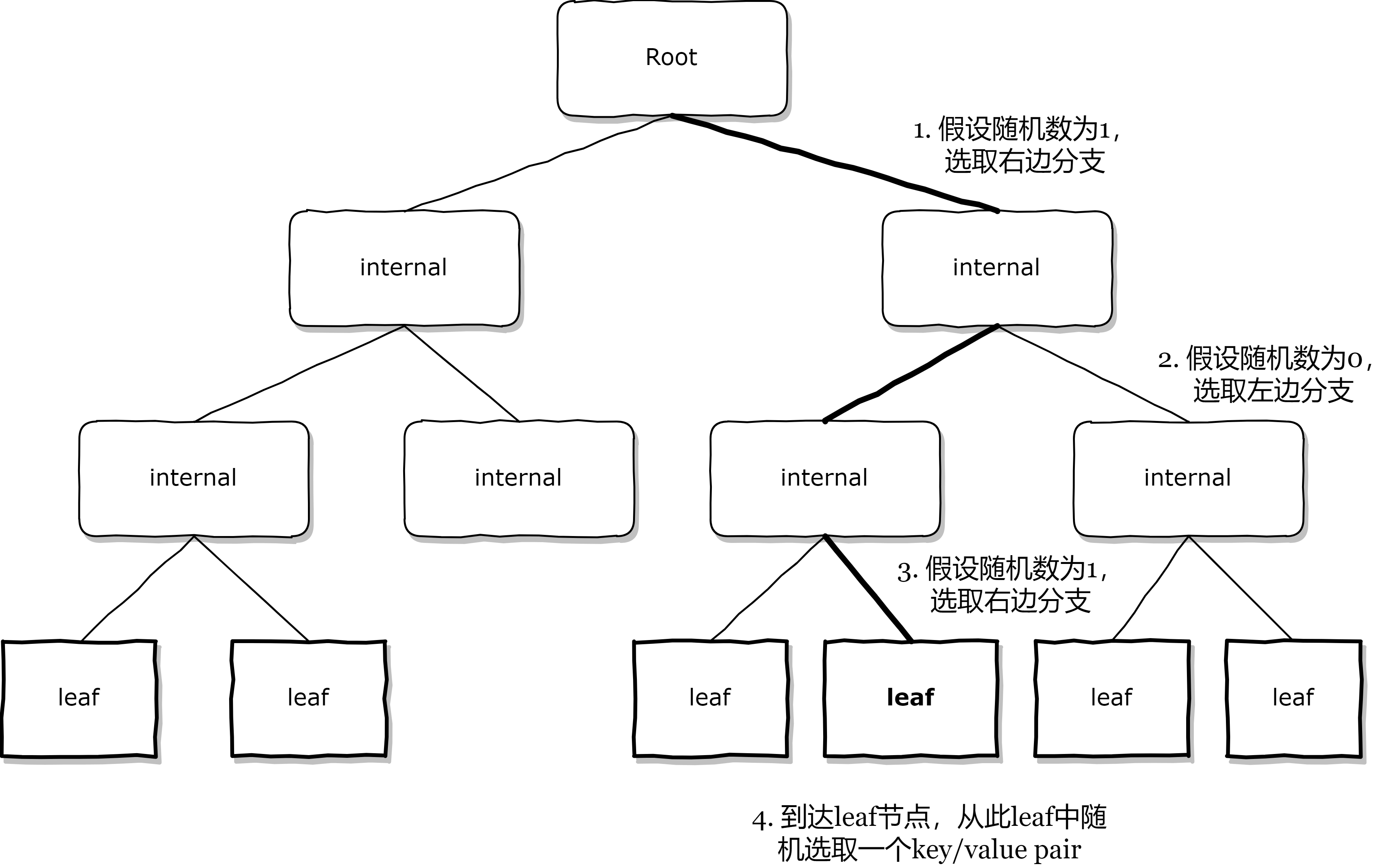
此外,random cursor还可以设置next_random_sample_size选项。如果设置了这个选项,假设为n,那么会把所有的叶子结点平分为n份,每次next被调用都会取这一份叶子结点集合里的第一个叶子节点里的一个随机key/value pair返回。这样能够更好地应对unbalanced tree。这种方式目前只有两个地方用到:一个是被内部用在对oplog 做sample,然后删除比较旧的oplog entries。另一个是如果上述“random descent”获取的那个key/value pair无效,就会自动使用这个备选逻辑来完成一次next。
3. sample命令的使用和实现
$sample是aggregate pipeline的一个stage。aggregate pipeline是MongoDB提供了一种“流水线式”进行数据数据处理的机制。使用时需要提供一个有序的stage序列。工作时,每个stage都把上一个stage的输出当作自己的输入,经过自身处理之后输出结果。
$sample的使用和行为
$sample 在mongo shell中使用命令如下:
use <database>
db.<collection>.aggregate(
[ { $sample: { size: <positive integer N> } }, <other stages...> ]
)
根据官方文档,这个命令在mongod上的具体行为有两种:
- random sort。首先读取上一个stage的全部输出,如果$sample是第一个stage就读取整个collection所有文档。然后对读取到的所有文档做一次随机排序,作为sample结果。
- random cursor。使用WiredTiger的random cursor完成sample。
random sort和random cursor都能保证采样得到的文档是随机、公平挑选的,能够反映出整个collection的大致情况,只是行为方式不一样。
sample执行时的行为不能由用户指定,而是自动由以下条件决定。如果下述三个条件全部成立,sample就走random cursor逻辑,否则就走random sort逻辑:
- sample是pipeline的第一个stage
- collection至少有100条文档
- N(也就是sample size)小于collection总文档数的5% 上述三个限制可以在内核代码的PipelineD::buildInnerQueryExecutor函数中找到。
$sample在mongos上的执行行为就是把aggregate请求分发给相关分片,然后做汇聚,把结果返回给用户。
下面分别介绍$sample在mongod和mongos上的实现。
$sample在mongod上的实现
如前面所说,$sample在mongod上有两种行为,分别是random sort和random cursor。
random sort行为的实现是 DocumentSourceSample::getNext()
- 首先扫描整个collection中的文档,
- 然后给每个文档都赋予一个随机数,按照此随机数对所有文档排序。
这里的排序是top-k排序,k是用户输入的sample size,算法使用的是c++标准库中的堆排序(make_heap,pop_heap,push_heap)。默认会把整个heap保存在内存中,同时限制了排序所使用的内存最大为100M,如果sample size比较大,很可能会超过这个限制,此时会报错。当然可以传递allowDiskUse参数来借助磁盘保存中间结果完成排序。
random cursor行为的实现是DocumentSourceSampleFromRandomCursor::getNext()
- 使用第2节所讲的random cursor获取一个随机的文档
- 如果此文档跟之前获取的文档有重复,则重试第一步,最多重试100次
从两者的实现可以看出来,random cursor行为是比较方便轻量的,random sort相比来说比较耗费资源。
$sample在mongos上的实现
执行逻辑如下所示: 1) mongos将$sample请求转发给保存有此collection数据的shard 2) mongod收到请求之后执行$sample,具体实现如上节所示,此外需要确保每个shard产生的文档序列是排好序的,便于mongos汇聚 - 对于 random sort,所有文档已经有了一个随机数,并且已按此随机数排好了序 - 对于random cursor,输出的每个文档被加上了一个随机数,这个随机数是递减的,使生成的文档序列也是“排好序的” 3) mongos将来自各个shard的已经有序的文档集合做归并排序 4) 将文档按顺序返回给用户直至数量达到sample size mongod给每个文档都加上了一个随机数,mongos做归并排序的依据就是这个随机数。而且每个mongod产生的sample结果都是有序的,所以mongos作归并排序是一个很轻量的操作,时间空间复杂度都是常数。而做归并排序的目的就是使采样结果更均匀,并不偏向某一shard。 上述过程可以用一张图表示,如下:
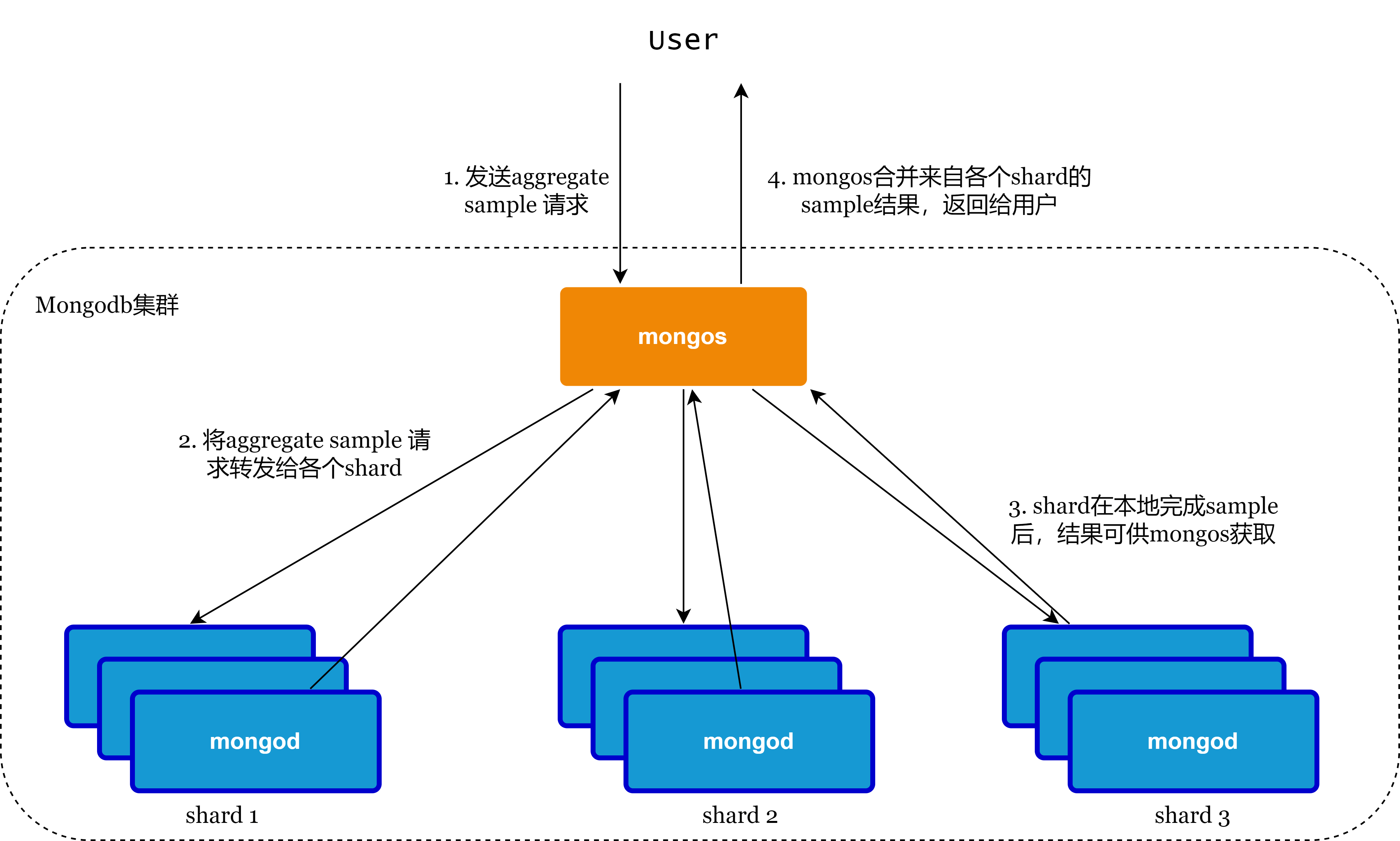
对于unsharded collection,$sample在mongos上执行和在副本集上执行没有差别,因为只会有一个shard参与进来。
对于sharded collection,$sample请求会被mongos转发到各个分片,其中sample size不变。但是这里存在一个问题:如果从mongos上执行$sample,输入的sample size 是collection文档总数的5%,期望走random cursor行为。而mongos把sample size原封不动发给mongod,造成在mongod上使用random sort内存排序。这个是因为每个mongod只能看到自己所存储的数据,结果sample size超过了文档数量的5%。这个问题正在与MongoDB官方沟通https://jira.mongodb.org/browse/SERVER-68623。目前可以使sample size < document count * 0.05 / shard number ,这样$sample会在mongod上走random cursor的逻辑,前提是数据已经自动均衡。
为什么要有两种行为
可以看出,random cursor应该是比较理想的采样方法,巧妙地利用B+树的结构达到随机采样的目的。但是random cursor的实现方式也决定了它的使用是有很多限制的,也就是之前提到的必须满足三个条件:
- 文档数大于100。如果一个collection的文档数小于100,B+树往往只有一个叶子节点,此时使用random cursor没有意义。
- sample必须是pipeline的第一个stage。random cursor必须在B+树上工作,如果sample stage的输入是前面的stage的输出,那就不存在B+树,也就不能用random cursor。
- sample size应该小于总文档数的5%。如果采样比例比较高,random cursor采到重复文档的概率也会比较高,会产生频繁的重试,甚至可能重试一百次之后直接报错。
random sort方式通用性好,在任何场景下都可以完成sample的目的,但是性能比较差,耗费资源比较多。
4. $sample的性能分析
为了评估sample的性能,在mongod上分别构造查询语句触发两种行为,mongod的配置均为2c2g,初始资源占用为cpu 0%,memory 59%,collection文档条数为1536w。实验结果如下:
| sample size | 行为 | 平均cpu使用 | 平均内存使用 | 采样总耗时 |
|---|---|---|---|---|
| 10000 | random cursor | 0% | 59% | 7s |
| 10000 | random sort | 50% | 59% | 76s |
| 700000 | random cursor | 12% | 59% | 195s |
| 700000 | random sort | 50% | 60% | 196s |
* sample size为700000时,random sort会报“sort exceeded memory limit of 100MB”错误,此次实验是传递了allowDiskUse参数,也就是借助磁盘进行排序。
观察上面表格,sample size为10000时,random cursor是非常快的,只用了7s,相比于random sort优势非常明显。random sort在耗时和cpu使用上都比较高,主要是因为random sort需要扫全表,然后做一个topk的堆排序。
sample size为700000时,random cursor和random sort的耗时差不多。因为random cursor每次在一个叶子结点内只取一个key/value pair,而且random cursor还有取到重复文档重试的逻辑,那么总共至少需要读取70w次叶子结点。而且这个B+树的高度为5,每次都要做random descent,导致random cursor的cpu也升高,在12%左右。此时random sort需要借助磁盘完成排序,cpu还是打满一个核的状态。
内存没什么变化,是因为WiredTiger不断地进行页面换入换出,维持cache size在80%左右。所以我们只需要关注cpu即可。
取random cursor的火焰图,可以发现时间主要耗在WiredTiger的页面读取上,这也是random cursor唯一比较耗费资源的地方。

取random sort的火焰图,可以看到有三部分比较耗时,从左到右依次为:
1) fromBsonWithMetaData,这是将WiredTiger中存储的byte array解析为bson,并嵌入一个 field name为”$sort”,field value为随机数的键值对的过程 2) WiredTiger的page in,是进行扫表并将每个page加载进内存的过程 3) DocumentSourceSort,是依据文档中 field name为”$sort”的那个随机数将文档进行堆排序的过程
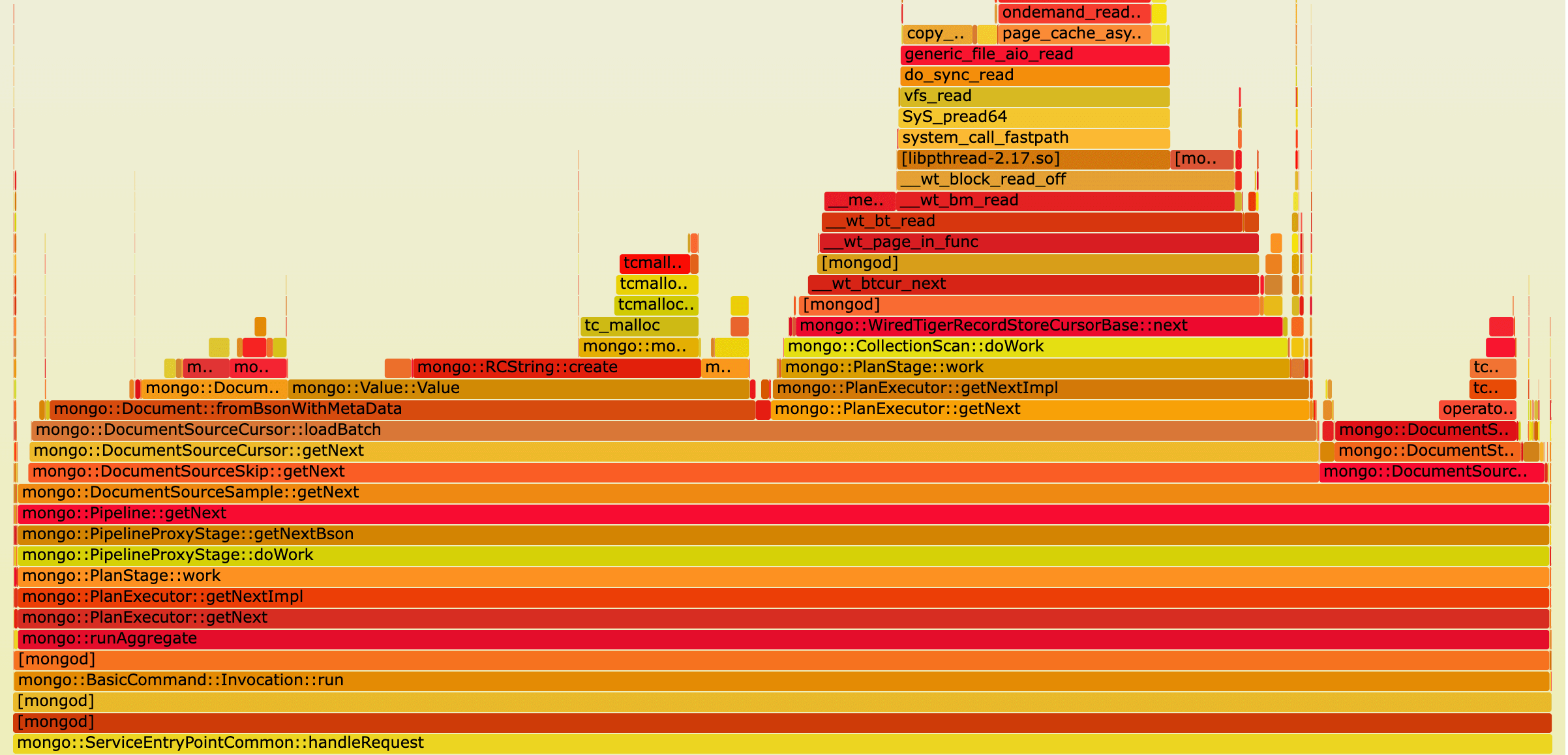
跟我们之前的分析是一致的。
5. 总结
本文详细介绍了MongoDB中$sample操作的底层实现,以及分析了$sample操作的性能。总体来说,如果要采样整个collection中的数据,在进行查询时要注意满足三个条件,让其走random cursor的逻辑,比较节省资源。其他情况会有正常的全表扫描和排序行为。
对于分片表来说,从mongos执行sample,行为可能会跟文档中描述的不一致。因为mongos将sample size直接透传给每个shard,而每个shard只能看到自己分片上的数据,导致更可能走random sort的逻辑。这个问题的具体讨论可以见https://jira.mongodb.org/browse/SERVER-68623。更保险的是,通过mongos执行sample之前,先看explain,确定每个shard上采用的哪种采样策略。