最近把CMU 15-665的课程跟着看了一遍,收获匪浅,基本弄清了DBMS的框架结构和一些关键的设计点。我看的是2019年的那期课程,老师讲的非常好,节奏很流畅,每一节课承上启下做的非常棒,不会让你因为看的是视频而一头雾水。总之非常推荐。
在听课期间结合《数据库系统概念》第六版,对每节课都做了自己的笔记。笔记简要概括了那一节课的内容,以及一些对我很有启发的地方,一些没听得很详细的地方就没有记录,想着以后碰到那块的东西再深究。这两天也趁热打铁重新翻了一下这个课程的课件和老师的讲义,据此按照我的理解做了一份思维导图。这份思维导图应该能很好的概括Disk-Oriented DBMS的主要脉络,这里也贴一下便于以后自己查阅。
lecture
lecture 01:introduction
主要介绍relation model 和 relation algebra。
几个点:
- database 和DBMS区别
- relation model、data model、schema、a relation、a tuple、primary key等概念以及含义
- query language分为两种procedural language和non-procedural language。SQL是一个declarative language,应该就是non-procedural language?
- 关系代数(relation algebra)是过程化的,元组关系演算(tuple relational calculus)和域关系演算(domain relational calculus)是非过程化的。
- A tuple is a set of attribute values (also known as its domain) in the relation.
- 关系代数的基本运算有select、projection、union、difference、product、rename。还有intersection、join
lecture 02:advanced SQL
主要讲SQL的一些高级语法和使用
几个点:
- Relational algebra is based on sets (unordered, no duplicates). SQL is based on bags (unordered, allows duplicates).
lecture 03:database storage Ⅰ
DBMS一般不会依赖OS的提供的disk与memory之间的page加载策略,而是自己实现。具体就是在memory中维护一个buffer pool,在disk上将数据以page为单位存储起来,对于page的查找需要借助page directory,总的来说非常像virtual memory。
主要解决两个问题:
- DBMS如何在disk上用file记录database? (本lecture)
- DBMS如何管理memory和disk之间数据的移动? (lecture 04)
几个点:
- 使用os来管理page并不可靠。所以DBMS一般自己实现disk与memory的数据交换。
- 数据在disk上的存储分为三层来讨论:file、page、tuple。
- file是os的概念
- page是为了适应磁盘的page
- file到page的组织一般采用heap file的方式
- heap file有两种实现方式:linked list, page directory
- page中存储的data分为两种:tuple-oriented、log-structured。
- 对于tuples的组织,通常采用slotted pages的方式。
- 对于log records的组织,通常就是用追加写入的方式,定期compact。
- tuple通常由header和data两部分组成。
- header保存metadata,如Visibility info (concurrency control)和Bit Map for NULL values。并不保存schema。
- data保存各个attribute的值。
- denormalize技术能够将一个tuple inline到另一个tuple中,这两个tuple通常分别属于两个有外键引用的relation。
- DBMS可以通过三元组(file id,page id,slot id/offset in page)来查找具体的tuple。
lecture 04:database storage Ⅱ
主要讲tuple中binary data的解析,以及OLTP以及OLAP各自的特点,以及存储的区别。
lecture 05: buffer pools
主要讲DBMS是如何使用以及管理buffer pool的。
几个点:
- buffer pool的目的
- 从空间以及时间上,让DBMS更好地控制对page的读写。(不要使用OS提供的disk-memory管理策略)
- buffer pool的组成
- an array of frames。frame是page的别名
- page table。包括dirty flag,ref counter
- latches
- replacement policy。LRU、Clock
- 针对buffer pool的常见的一些优化方法
- multiple buffer pools
- prefetching
- scan share
- buffer pool bypass
- better replacement policy。LRU-K、Priority hints、Localization
- 其他
- 如何处理脏页?DBMS可以定期遍历页表并将脏页写入磁盘。需要注意的是,在写入日志记录之前,不要将脏页写回磁盘。
lecture 06: Hash Tables
哈希表在数据库中被广泛使用,这一节主要讲了哈希表是如何实现的。
对于一个哈希表的实现,通常会从两方面进行设计:
- hash function。如何将一个很大的key空间映射到一个很小的值空间内。需要在速度和哈希碰撞(collision)之间做一个折中。
- hash scheme。如何存储数据以及如何解决哈希碰撞。需要在时间和空间上做一个trade-off。要么多花点时间来搜索,要么要花点空间解决哈希碰撞。
hash table的结构一般是<hashcode, bucket>的形式,hashcode是hash function的输出,bucket是一个存储单位,能够存放一条或者多条记录。
hash function
- 以key为输入,输出一个整数作为这个key的hash
- 同样的输入总能得到同样的输出
- 不需要使用SHA-256这样的cryptography hash function,因为不需要考虑key的内容被泄露。
hash scheme
- 静态散列 Static Hashing Schemes
这种scheme下,哈希表的大小是固定的,如果需要增加哈希表的size只能重新构建一个大的哈希表,并把原来哈希表的内容导入进去。
对哈希冲突的解决策略有如下几种:
- open addressing。
- Linear Probe Hashing 线性探查法
- Robin Hood Hashing
- Cuckoo Hashing
- close addressing
- Chained Hashing 利用链表把overflow bucket链接起来
- 动态散列 Dynamic Hashing Schemes
随着数据库的使用,哈希表存储的内容不可避免的会越来越多,当需要更大size的哈希表的时候,静态散列只能重新构建哈希表,并且重新选择哈希函数。动态散列允许哈希函数动态改变,以适应数据库增大或者缩小的需要。
- Extendible Hashing。散列函数产生的值范围较大,一般为b个bit的二进制整数,但是一开始并不需要创建2的b次方个bucket,而是在插入记录时按需建桶的。在任意时刻,都只使用散列值的 前 i 个bit,用来定位具体的bucket,i的值永远满足
0<i<=b。随着存储的内容变多,i 只需要增加一位,bucket的数量就会翻倍。 - Linear Hashing 利用了线性代数的知识,想了解的话可以参考 https://www.jianshu.com/p/0bf2400786f6
lecture 07: tree indexes Ⅰ
有两种基本类型的索引:
- 顺序索引
- 哈希索引
主要讲B+树这个数据结构。现在几乎所有的DBMS都使用B+树来支持order-preserving indexes。
B+树是一个M路的搜索树,同时具有如下特点:
- It is perfectly balanced (i.e., every leaf node is at the same depth).
- Every inner node other than the root is at least half full (M/2 − 1 <= num of keys <= M − 1).
- Every inner node with k keys has k+1 non-null children.
B+树中的每一个节点都保存一个<key, value>的数组:
- 每个数组都是按key排序
- 内节点(inner node)中的values中是指向其他节点的指针
- 叶子节点(leaf node)中的values可以分为两种:
- record ids:一个record id是指向tuple真实地址的指针
- tuples
B树与B+树的区别:
- B树中的tuple data可以存在任何节点中,B+树中的tuple data只能存在leaf nodes中
- 所以B树中不会重复存储tuple data,占用空间比较小,但是搜索代价不稳定
- 而且B树在删除插入代价比B+树大,因为一般B+树再删除插入values只需要更改leaf node,而、B树很可能需要rebalance。
其他:
- B +树的最佳节点大小取决于磁盘的速度。磁盘越慢,节点越大,想法是通过尽可能多的键/值对来分摊从磁盘读取节点到内存的成本。
- 也可以自定义合并阈值,并不一定是half full,延迟合并操作可能会减少树调整的次数,提高性能。
- 对于叶子节点中的key可以前缀压缩,对于非叶子节点中的key可以后缀截断(也就是只存储前缀即可实现路由的功能)
- bulk insert能够提高插入性能,是先将此bulk的数据构建一个小的B+树,然后将此树直接融合到大的B+树中。
lecture 08: tree indexes II
主要介绍了其他的几种索引类型,Partial Indexes、Covering Indexes、Index Include ColumnsFunction/Expression Indexes;以及其他几种索引结构,比如trie tree、 radix tree、inverted index。
lecture 09: Index Concurrency Control
本节主要讲在使用index时的一些并发控制,也就是latch。
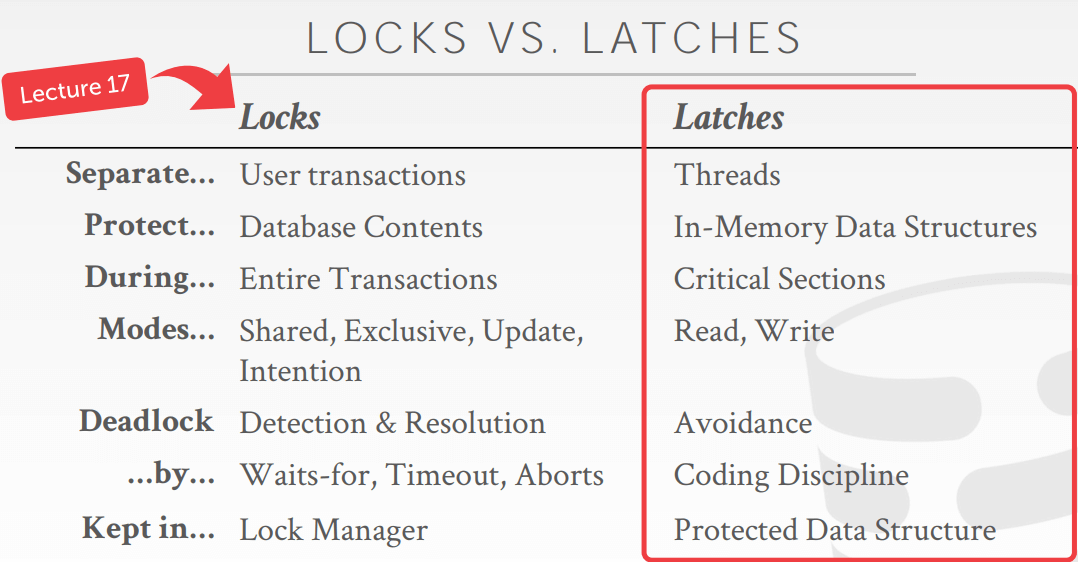
- lock和latch的区别:
- latch是对内存数据结构提供互斥访问的一种机制,Lock作用于数据库对象比如table,index等
- Latch是瞬间的占用,释放,用来应对多线程的访问;Lock的释放需要等到事务正确的结束,他占用的时间长短由事务大小决定,用来做事务之间的隔离性。
- latch在使用上很类似日常所说的读写锁。而lock是一种特殊的锁,需要具有rollback机制
- concurrency control protocols 是DBMS用来保证并发操作对于共享对象的正确性的方法。正确性可以从两方面来衡量:
- logical correctness 我看到的数据是否是预期的
- physical correctness 对象的内部数据是否正常
- 对于B+树的加锁主要考虑两个问题:多线程同时访问同一个node的安全性;一个线程在遍历树,另一个线程在split/merge node(也就是rebalance)。这两个问题可以通过一种latch crabbing/coupling的protocol来解决。
- latch crabbing是这样的一种策略:在获取一个child node的latch之前,先获取parent node的latch,并且只有当child node是安全的(也就是此insert或者delete操作完成之后此节点不会发生split或者merge),才会获取child node的latch,并且释放parent node的latch。
- 对于find来说:从根节点开始向下遍历,不断获取子节点的R latch,释放父节点的latch
- 对于insert/delete来说:从根节点开始向下遍历,不断获取W latch,获取到W latch之后判断当前节点是否是安全的,如果是安全的就释放所有祖先上的latch。
- latch crabbing是这样的一种策略:在获取一个child node的latch之前,先获取parent node的latch,并且只有当child node是安全的(也就是此insert或者delete操作完成之后此节点不会发生split或者merge),才会获取child node的latch,并且释放parent node的latch。
lecture 10:Sorting & Aggregation Algorithms
table中的tuples是无序的,但是许多操作都需要排序,例如ORDER BY, GROUP BY, JOIN, DISTINCT。对于clustered B+tree,可以从左到右遍历叶子节点得到有序的tuple。对于unclustered B+tree一般通过外部归并排序来做。
对于GROUP BY,DISTINCT这些不需要排序的Aggregation场景,使用hashing的方法相比sort是一个更好的选择。hashing方法也能在内存不足的情况下借助磁盘完成任务。
lecture 11:join algorithms
在使用数据库时,我们常常遵从常用的设计范式,而这些范式的核心目的就是减少重复。而在读取数据库时又常常需要把这些数据“组装”起来使用,这就是join的作用。
对于join的理想实现,是让两个table 中的tuple做笛卡尔乘积,生成一个新的table,里面存放join的结果。但是基本不可能这么做,因为一般table中的tuple有很多,另外可能一个tuple有很多column,生成的结果会非常大。
有很多算法来减少join操作的开销,但没有哪一种是适合所有场景的。
- nested loop join
- stupid:多层for循环,单位是tuple
- block:也是多层for循环,但是单位是page或者block
- index:借助index查找join key相等的tuple
- sort-merge join。分为两阶段
- sort阶段将两个table按照join key进行排序,可以使用上一节讲的外排序
- merge阶段分别两个有序的table,将两个join key一致的tuple组合起来作为join的结果
- hash join。也分为两阶段
- build阶段,使用一个hash函数h根据join key将outer relation 建立一个hash table。(也可以在这一阶段创建一个bloom filter,加速probe阶段)
- probe阶段,对inner relation中的每一个tuple,都使用hash函数h在上面的hash table中搜索,寻找outer relation中join key值相同的tuple。
- grace hash join
lecture 12: Query Processing I
query processing 是从数据库中进行数据操作所进行的一系列动作。一般包括三个步骤:语法解析与翻译;优化;执行。也就是从用户输入SQL语句到得到结果的这一个过程。
- 语法解析与翻译。SQL语言适合人使用,但是并不适合机器,因此一般将查询语句翻译为以关系代数为基础的表达式。这一过程类似于编译器的语法分析器。
- 优化。同一个查询语句可以翻译为不同的关系代数表达式,而且在关系代数表达式上可以建立的不同查询执行计划,不同的查询计划会有不同的代价。构造具有最小查询代价的查询计划叫做查询优化。
- 加了“如何执行”注释的关系代数运算称为“计算原语”。(例如走index scan并操作,走seq scan的或操作)
- 用于执行一个查询的原语操作序列成为查询执行计划。
- 查询执行引擎接受一个查询计划,执行该计划并将结果返回给查询。
- 执行。以单个关系运算的执行为基础,多个运算组成的表达式一般有两种执行方式:
- Materialization Model。从树的最底层开始,每个运算的输入是更低一层的输出,输出是一个临时relation。也就是说所有中间结果都被作为临时relation被创建,甚至被写到磁盘。
- pipeline Model。对于一个tuple来说,在表达式中被流水线化地处理。中间结果不必长时间保存,并且能够最大限度重用各个操作的代码。在实现上有两种方式:
- demand-drivern pipeline,需求驱动的流水线,树的顶层不断向底层发送获取tuples的请求。每个操作都可以用迭代器iterator的方式实现,实现简单。
- producer-drivern pipeline,生产者驱动的流水线,树的低层积极地生成tuples
对于多种可能的查询计算计划,希望根据代价对它们作比较,并选择最佳方案。一般,代价是由查询计划对各种资源(CPU时间,磁盘存取时间,并行/分布式数据库通信开销)的使用情况来度量的。磁盘通常是最主要的代价。
lecture 13:Query Processing II
主要讨论了基于关系数据模型的并行数据库。
- interquery parallelism,多个查询并行执行。主要是为了提高事务处理能力
- intraquery parallelism,单个查询在多个处理器和磁盘上并行执行。有两种并行方式
- intraoperation parallelism,操作内并行,比如并行地排序,并行作join。见18.5章
- interoperation parallelism,操作间并行。见18.6章
即使我们能把一个操作非常高效地并行处理,但是磁盘还是很可能会成为瓶颈。
- IO parallelism。将一个relation划分到多张磁盘上,来分散IO的压力。常用的形式就是水平分区,把一个relation中的所有tuple分散到多个磁盘上。有好几种划分策略
- round-robin。对于点查和范围查询效率都不高
- hash partitioning。对于扫表和点查很有效。但是范围查询效率不高
- range partitioning。点查和范围查询都还可以。但是出现skew的可能性比较大。
- 对于skew的处理 见18.2.3章
lecture 14 & 15:Query Planning & Optimization
这一节和下一节主要讲查询优化的东西。query optimization是一个NP-HARD的问题,也是DBMS中最难的问题。
SQL是命令式的,正如lecture12中所说,对于一个给定的用户查询,DBMS可以用不同的关系代数表达式去表示它,每一个关系代数表达式也能得到多种多样的查询执行计划。query optimization的目的就是对于一个到来的查询,能够选出一个“最有效”的查询执行计划。
首先要知道所有的可用的查询执行计划。给定一个用户查询,生成查询计划有两个步骤:
- 产生逻辑上与给定关系代数表达式等价的表达式。通过等价规则来进行(13.2章),也叫做query rewriting
- 对所产生的表达式以不同方式做注释,产生不同的查询计划
生成路径如下: SQL语句 –> 关系代数表达式 –>(加注释)–> 计算原语 –>(组装)–> 查询计划。
有两种常用的方式来进行查询优化,也就是选出一个最有效的查询执行计划:
- Heuristics/Rules。启发式/基于规则。根据经验设置一些规则,对于不符合此规则的查询执行计划不视作可能的最有效查询执行计划。通常用作缩小搜索空间(减少需要考虑的查询执行计划的数量),降低查询优化本身的代价。一些常用的规则有:
- Predicate Push-down。尽早执行filter运算
- Projections Push down。尽早执行projection运算
- Expression Simplification。
- Cost-based Search。基于代价的搜索方法。
- 代价的计算并不依靠查询执行计划的真实执行。DBMS会在内部的catalog中存储每个relation的统计信息——tuple个数、指定属性的value distribution(直方图)、索引等等。直方图并不需要保存每个值的信息,可以把许多值用一个bucket来表示,来减小直方图的大小。
针对单个relation的OLTP查询优化比较简单,通常只需要挑选最优的索引。
对于嵌套查询,比如where里面的查询子句,通常是将子句作为一个单独的函数,将他的输出写入到一个临时的表。
lecture 16:Concurrency Control Theory
这节主要讲事务transaction。对事务的要求一般采用ACID来描述:
- Atomicity。All or nothing
- approach 1:Logging
- approach 2:Shadow Paging
- Consistency。要求事务执行后能够保持数据库的一致性,例如主码约束、参照完整性、check约束等。由事务编写者负责。
- Isolation。每个事务都感觉不到系统中有其他事务在并发执行。
- Durability。事务commit之后,所有的更改都是持久化的,即使DBMS崩溃了
Atomicity和Durability主要由recovery system负责。这里主要讲实现Isolation的并发控制系统的内容。
为了高效,使用并行的方式执行transactions,但是并发会带来很多并发问题。对于确保并发执行事务不“出错”。需要做两件事:
- we need formal correctness criteria to determine whether an interleaving is valid
- 定义:database被视作一个data object的固定集合(A,B,C……)。(不讨论insert和delete,这两者会导致新的问题——phantom problem)
- 定义:transaction被视作一个读写操作的序列(R(A), W(B), R(B)……)
- correctness criteria就是 ACID。
- 识别哪些并发情况是正确的,哪些是不正确的
- 如果一个schedule等同于某个serial execution,那么这个schedule就是正确的。这种schedule也叫做serializable schedule。
- 什么schedule?多个transaction的operation一种交错排列。serial schedule就是多个transaction顺序排列。
- 什么是等同?对于任何一个database state,两个schedule执行后的effect等同。
- conflict。如果两个来自不同transaction的operations,操作同一个data object,并且至少一个是write。那么这两个operation就有了conflict。
- Read-Write conflicts。也叫做unrepeatable reads
- Write-Read conflicts。也叫做reading uncommitted data,“dirty reads”
- Wirte-Write conflicts。也叫做overwriting uncommitted data
- 如果一个schedule等同于某个serial execution,那么这个schedule就是正确的。这种schedule也叫做serializable schedule。
- 如何做到正确。可以通过检查一个schedule是否存在conflict 来判断是否是serializable schedule
- conflict equivalent
- conflict serializable。通过precedence graph实现
- 那么如何产生一个serializable schedule,也就是如何协调conflict来做到并行且安全的schedule:
- pessimistic。例如two-phase locking
- optimistic。例如 timestamp ordering
lecture 17:Two-Phase Locking
这一节承接lecture 16的内容,主要讲2PL,这是一个能生成serializable schedule 的一个算法。
如何证明根据two-phase locking protocol生成的schedule是一个serializable schedule? 
2PL的问题:
- 级联回滚,cascading aborts。普通的2PL不能阻止dirty reads,可能导致读到了脏数据的事务级联回滚。strict two-phase locking protocol(要求事务commit之前不得释放所有的X锁)和rigorous two-phase locking protocol(要求事务commit之前不得释放所有锁)可以解决。
- 死锁,deadlock。主要有两种解决方法(感觉主要就是悲观和乐观的区别)
- deadlock prevention,死锁预防
- deadlock detection & recovery,死锁检测和恢复
锁是由lock manager统一管理,并且有不同粒度的锁。将database抽象成一棵树,对一个节点加锁,通常也意味着要对子树的访问有所限制。意向锁
lecture 18:Timestamp Ordering
这一节也算是承接lecture 16的内容,主要讲乐观的生成serializable schedule 的一个算法——基于时间戳的协议。“时间戳排序协议保证冲突可串行化,这是因为冲突操作按时间戳顺序进行处理。也保证无死锁,因为不存在事务等待。但是可能导致长事务饿死。”
主要讲了两个算法:Basic Timestamp Ordering Protocol、Optimistic Concurrency Control
lecture 16中说到 “不讨论insert和delete,这两者会导致新的问题——phantom problem”。2PL不能解决这种问题,意向锁可以解决phantom的问题。另一个解决phantom比较常用的方式是通过predicate locking来解决——也就是对指定表达式加锁(比如where age=18、where age<20)。但是predicate locking很难实现,而且开销很大,如果指定字段上有index,一般使用index locking的方法。
下面的内容来自2018年课程视频,因为2019年没讲。isolation levels,是说一个transaction向其他正在并行运行的txn所暴露的程度等级。越多地将一个txn未提交的内容暴露出去,并发度就越高。根据dirty reads、unrepeatable reads、phantom reads将隔离等级从高到低分为四种:
- serializable。上面三种情况都不允许
- repeatable reads。可能会有phantom reads
- read committed。可能会有unrepeatable reads和phantom reads
- read uncommitted。三种情况都允许

lecture 19:Multi-Version Concurrency Control

MVCC的design decision主要有:
- concurrency control protocol
- 可以使用2PL,也可以使用timestamp ordering
- version storage
- garbage collection
- index management
lecture 20 : Logging Schemes
这一节主要讲DBMS是如何应对故障的。也就是recovery schema(恢复机制)是如何将数据库从故障中恢复到一致的状态,以及将数据库的不可用时间缩减到最短(高可用 high availability)。保证事务的ACD。
故障的分类:
- transaction failure。
- logical error。比如非法输入
- system error。比如死锁
- system crash。硬件故障,或者DBMS、操作系统故障,但是disk不受影响(fail-stop assumption)。
- disk failure。没有DBMS可以处理这种情况,只能依靠周期性转储来恢复database。
目标:
- 如果DBMS说某个事务已经提交了,那么这个事务的所有更改都应该已经持久化
- 如果某个事务aborted,那么不允许这个事务所做的任何更改
故障恢复算法分为两部分:
- 在正常处理事务时采取措施,保证有足够的信息可以用于故障恢复。(也就是视频课程这一节主要讲的内容)
- 故障发生后采取措施,将数据库恢复到某个一致性的状态。(lecture 21)
DBMS如何支持故障恢复,取决于它是如何管理buffer pool的。
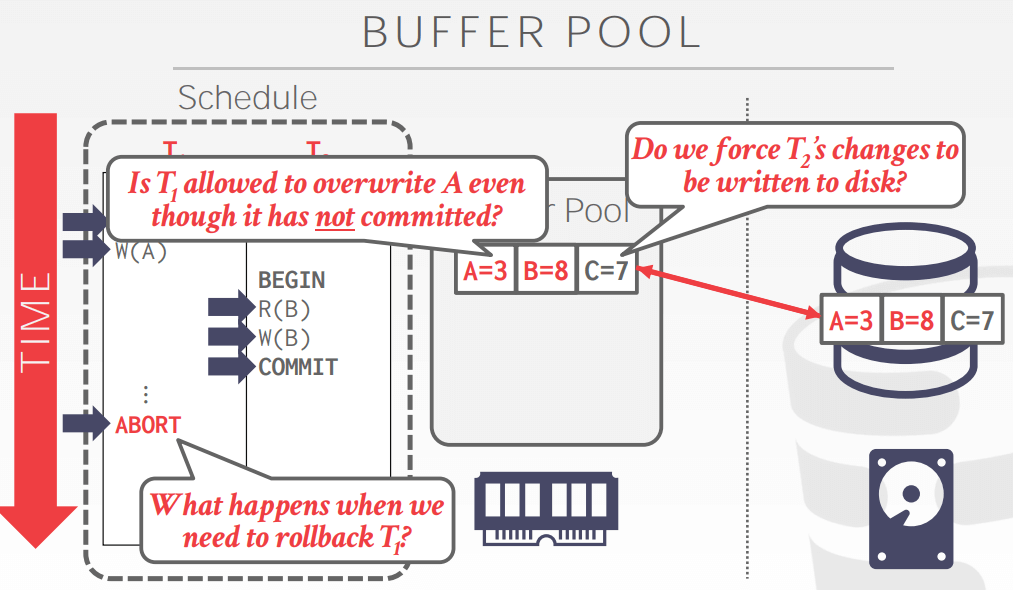
如上图,在T1 abort 之前,T2 commit。DBMS在两个问题上会有取舍:
- 一个事务真正commit之前,是否强制将其更改写入到磁盘 (force or not)
- 在将buffer pool的内容刷新到磁盘上时,是否允许未提交事务的更改写入到磁盘 (steal or not)
现在广泛使用的WAL策略,其中一个原因就是它支持steal+no-force的buffer pool管理策略,比较高效。 WAL(write-ahead logging)规则:内存中的数据块输出到磁盘前,所有与该数据块中数据有关的日志记录必须已经输出到稳定存储器。
一个事务的相关日志记录写入到稳定存储器之后,这个事务才被认为是committed。
要支持steal+no-force的buffer pool管理策略,就要解决两个问题:
- 事务已经提交,但是它对数据库的修改仅仅存在于内存中,还没同步修改磁盘,然后crash。(redo)
- 事务还未提交,但是已经修改了数据库,且同步到了磁盘上,然后crash,这个事务需要回滚。(undo)
一条log record至少要包含:
- transaction id
- object id
- old value(用来做undo)
- new value(用来做redo)
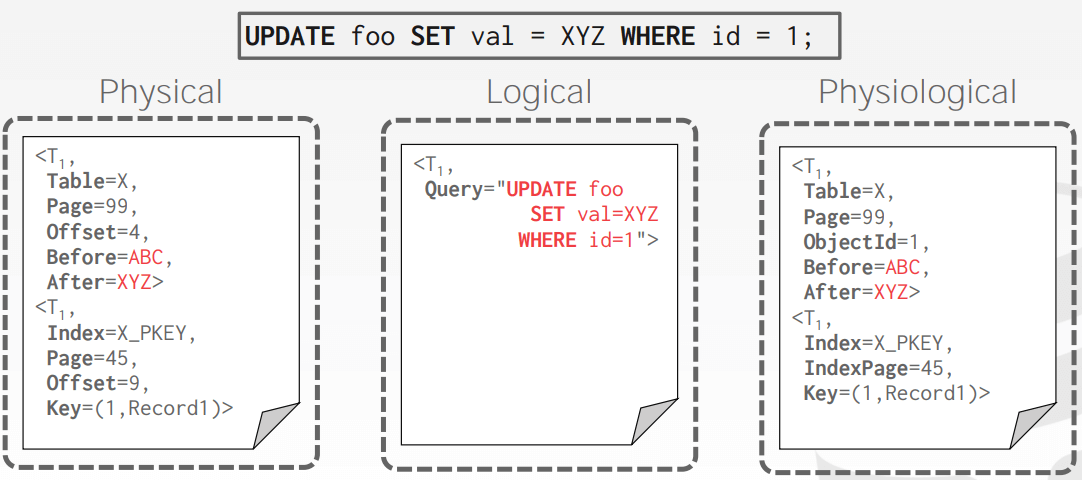
另外,日志以何种形式记录呢?
- Physical Logging。以raw bytes的形式记录对数据库的修改
- Logical Logging
- Physiological Logging
系统发生故障后,必须检查日志,决定哪些事务需要redo,哪些事务需要undo。搜索整个日志来确定该信息非常耗时,因此引入了检查点checkpoint。
一个简单的检查点创建过程如下:
- 此过程中,不允许事务执行更新操作,如写缓冲块或写日志记录
- 将当前位于主存的所有日志记录输出到稳定存储器
- 将所有修改的缓冲块输出到磁盘
- 将一个日志记录
<checkpoint L>输出到稳定存储器,其中L是此创建点创建过程中尚在活跃的事务列表 checkpoint是怎么创建的,多久创建一次,也是一个需要trade-off的问题。
对于disk failure的情况,一般采用转储(dump)的方式:比如一天一次进行备份。转储的方式一般也要求转储过程中不能有事务处于活跃状态,类似于检查点。不过都有改进措施。
lecture 21:ARIES Database Crash Recovery Algorithms
这一节主要讲ARIES,Algorithms for Recovery and Isolation Exploiting Semantics,一种故障恢复算法。
每个log record额外包含一个全局唯一的编号,就是log sequence number LSN。DBMS的各个组件通过LSN来追踪日志。
三个阶段:
- 分析阶段,analysis pass
- redo阶段,redo pass
- undo阶段,undo pass
没仔细听,可以重新看一下课程视频,看一下别人的笔记https://www.jianshu.com/p/ea61881309df
lecture 22:Introduction to Distributed Databases
Distributed DBMSs的架构主要有:
- shared-memory
- shared-disk。这种也是很常见的,因为cpu-memory这些计算资源是无状态的,可以很好地创建销毁迁移。(类似于存算分离)
- shared-nothing。节点之间只通过network来交流。
design issues:
- application如何查询数据
- 如何执行query
- 如何保持一致性
hash partitioning,consistent hashing
分布式环境下的事务需要一个协调者coordinator,协调者的选取有两种方式:
- centralized,有一个全局的协调者
- decentralized,节点间自己决定
lecture 23:distributed OLTP database
- OLTP特点:
- 一个事务的运行时间较短
- footprint比较小
- 重复的操作
拜占庭算法(也就是区块链的共识算法)
atomic commit protocol,一个涉及到多节点的事务如何安全地提交,做法有:
- two-phase commit
- three-phase commit(很少用)
- paxos
- raft
- zab(apache zookeeper)
- viewstamped replication
two-phase commit需要所有的节点都同意commit,才算真正的commit。 paxos只需要大多数的节点同意commit,就算commit。
replication:
- configuration:
- approach 1:master-replica。不需要使用atomic commit protocol
- approach 2:multi-master。需要使用atomic commit protocol
- k-safety。确保每份数据至少被replicate k份
- propagation scheme。通知客户端commit完成之前是否把事务的更改更新到replicas
- synchronous,也叫strong consistency
- asynchronous,也叫eventual consistency
- propagation timing。
- approach 1:continuous
- approach 2:on commit
CAP理论:
lecture 24:distributed OLAP databases
query plan fragment
- approach 1:physical operators,把一个query plan分成partition-specific fragment
- approach 2:rewrite SQL,把初始的query改写为partition-specific queries
cloud system:
- approach 1:managed DBMSs。云厂商托管数据库,数据库本身是不知道自己运行在云环境中
- approach 2:cloud-native DBMS。为云环境所设计,通常基于shared-disk
serverless database
lecture 25:Oracle in-memory databases
可以看出近几年Oracle的主要工作方向就是in-memory。
思维导图

参考链接
- 《CMU15-445课程》https://15445.courses.cs.cmu.edu/fall2019/schedule.html
- 《别人的学习笔记》https://www.jianshu.com/nb/36265841
- 《课程视频》https://www.bilibili.com/video/BV1q741127SQ
- 2018年的课程视频:https://www.bilibili.com/video/BV1ft411B7nz